Architectural Evolution: 强化学习系统
从零开始的RL工程学习之路
前言说点什么
说起来几年前就在支持类似RLHF的工作了, 但是那时候还是个愣头青, 也不知道什么是RL, 只知道有个算法模型需要我做各种各样的工程. 功能实现占大头, 效率占小头. 直到最后也没明白这些工程到底如何支持LLM的RL训练的
后来换了东家, 因为一些特殊情况, 需要我这个工程和一个算法同学研究出《在某个场景下, 用RL替换人工的策略决策》. 我一听懵了, 完全没有听说的东西, 纯想象造出来啊? 不过随之而来的就行兴趣溢出, 满心欢喜地开始了学习和实践之路
引言:为什么我们需要演进?
在初期,我们的核心痛点是如何将复杂的业务仿真(Simulation)与算法模型(Agent)连接起来。随着业务场景的复杂度提升,数据吞吐量成为了瓶颈,单机训练不再可行,异构算力的浪费也日益凸显。
以下是我们的四个演进阶段:
第一阶段:解耦与探索 —— gRPC-Gym 架构
关键词:微服务化、ProtoBuf、语言无关
在项目的起步阶段,仿真环境(Environment)往往是现成的(可能是 C++ 或 Java 编写),而算法侧(Agent)使用 Python/PyTorch。
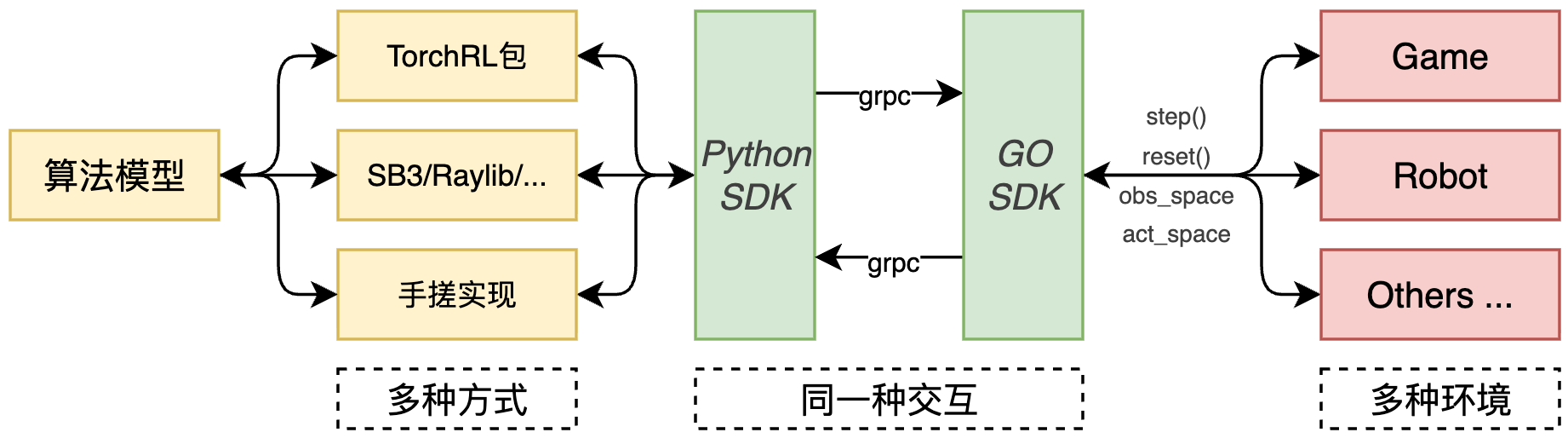
架构特点
Gym Interface over gRPC:我们在仿真器和算法之间建立了一条 gRPC 管道。
跨语言支持:无论仿真器是 C++ 还是 Golang,通过 ProtoBuf 定义状态(State)和动作(Action),都能轻松对接。
遇到的挑战
通信模式的低效:采用了同步阻塞 (Synchronous Blocking) 的通信模式。Env 必须等待 Agent 返回 Action 才能继续,网络往返时间(RTT)成为了系统的硬性瓶颈,导致严重的 IO Bound (IO 密集型) 问题。
序列化开销(Serialization Overhead):每次交互产生的高维状态矩阵都需要在 ProtoBuf 和 Tensor 格式之间进行深拷贝和转换。CPU 大量算力被消耗在
memcpy和编解码过程中,而非核心计算逻辑。
总结:解决了“跨语言解耦”的功能性问题,但因高频小包传输和序列化成本,无法满足高性能训练需求。
第二阶段:标准化与原生化 —— 拥抱 TorchRL 范式
关键词:TensorDict、Composable、零拷贝
为了消除序列化开销,我们将架构向 PyTorch 原生生态迁移,采用了类似 TorchRL 的设计哲学。
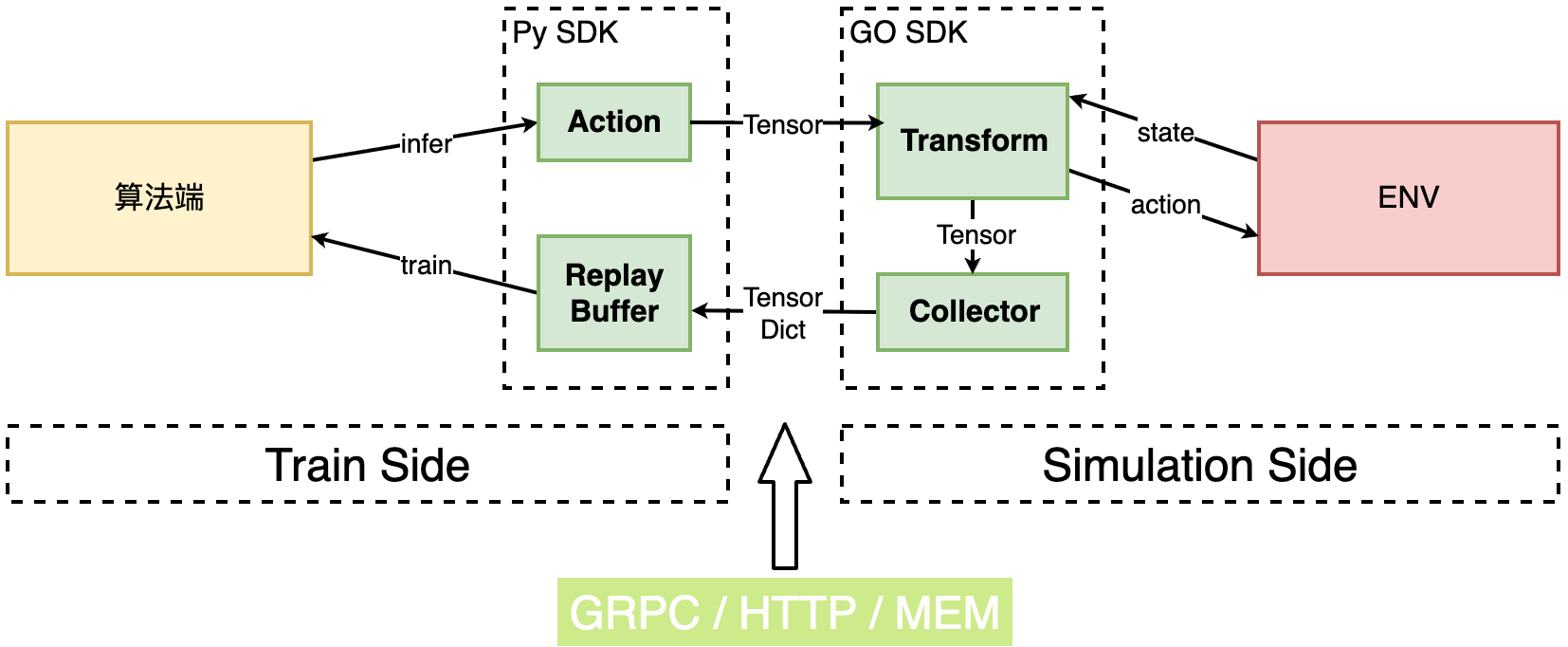
架构升级
TensorDict 统一数据流:
废弃了散乱的 Python Dictionary 或 Proto 对象。
引入
TensorDict作为数据载体,从环境输出的那一刻起,数据就是 Tensor 格式。这使得数据在 Buffer、Model 和 Loss 之间的传递变得极其高效,支持批量操作(Batch operations)无需额外的
stack/pad逻辑。
模块化原语(Primitives):
- 将环境变换(Transform)、数据收集(Collector)和重放缓冲区(ReplayBuffer)标准化。
收益
开发效率:算法工程师专注于 Tensor 操作,不再处理底层通信代码。
性能提升:减少了 Python-C++ 边界的上下文切换,数据流转速度提升数倍。
通信模式优化:从单步交互升级为基于轨迹 (Trajectory-based) 的批量传输。Actor 在本地完成完整的数据采集后,通过高速通道将打包好的
TensorDict异步发送给 Buffer。这种异步、批量、大粒度的通信模式,显著提升了网络带宽利用率。零拷贝机制:基于 TensorDict 和共享内存技术,数据从生成到传输直接以 Tensor 字节流形式存在,消除了 ProtoBuf 序列化/反序列化的 CPU 开销。
第三阶段:算力爆发 —— 全节点分布式训练 (Fully Distributed)
关键词:Scale Out (横向扩展)、DDP、IMPALA、Async Collection
随着模型参数量的增加和对 Sample Efficiency 的追求,单机多卡已无法满足需求。
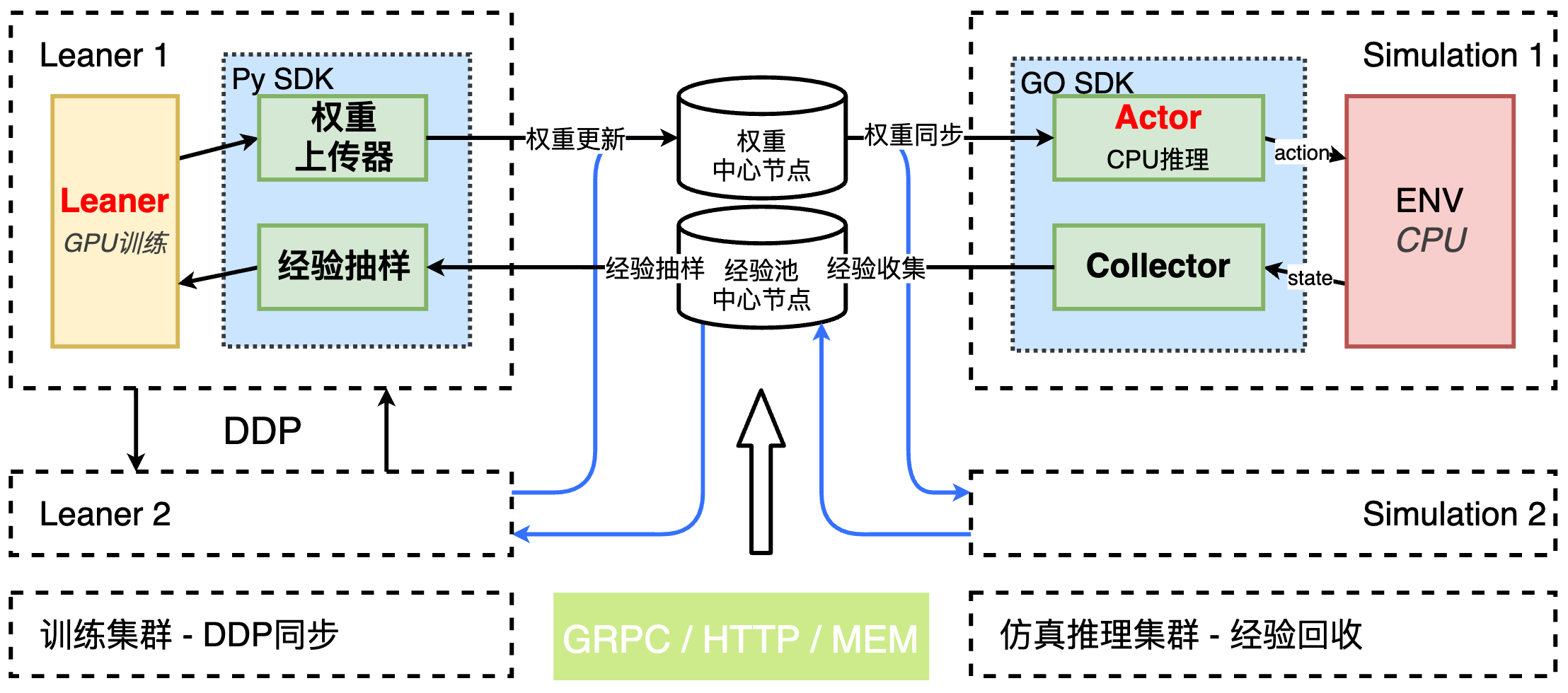
架构变革
从 Parameter Server 到 Ring All-Reduce:
- 不再依赖中心化的参数服务器,而是让所有计算节点参与梯度同步。
Actor-Learner 分离架构:
Actors(采样节点):成百上千个 CPU 核心并行运行仿真环境,利用 TorchRL 的 Collector 将数据极速写入共享内存或高速队列。
Learners(训练节点):GPU 集群专注于消费数据并更新梯度。
异步更新与偏差修正 (Asynchronous Update & Bias Correction):
针对 PPO 等 On-Policy 算法,Learner 更新参数时 Actor 可能仍在使用旧参数采样(Policy Lag)。
为了实现流水线并行,我们采用 APPO (Async PPO) 或 IMPALA 范式。
通过在 Learner 端引入 V-Trace 或 Importance Sampling 对旧策略产生的样本进行数学修正,在保证收敛性的前提下实现了计算与通信的完全重叠。
局限性分析
虽然第三阶段通过 Scale Out 解决了算力总量问题,但对于 Sequence Modeling (如 Transformer) 类模型仍存在瓶颈:
推理效率低下:Actor 端若运行完整 Transformer,随着 Context Length 增加,计算量呈 O(_L_2) 增长,导致 CPU 无法负担。
O(L2)
资源错配:若给 Actor 配备 GPU,因推理的自回归特性,显存大量被 KV-Cache 占用且利用率低,造成资源浪费。
核心突破:吞吐量(FPS)不再受限于单个节点的 CPU 核心数,而是随着集群规模线性增长。
第四阶段:极致效能 —— 引入 PD (Prefill-Decode) 异构计算架构
关键词:Decoupling (解耦)、Context Offloading、异构计算、KV Cache
这是最激动人心的架构升级。在处理基于 Transformer 的 Agent(如 Decision Transformer)或大模型 RL 时,我们发现**推理(生成动作)与训练(反向传播)**的计算特征截然不同。
借鉴 LLM 推理中的 Prefill/Decode 分离思想,我们重构了计算流:
1. 异构算力分配 (PD 映射)
P 阶段 (Prefill / Training 模式):
计算特征:高并行、高吞吐、大规模 Batch 处理。类似于 LLM 的 Prefill 阶段。
硬件分配:GPU 集群。Learner 节点负责对收集到的历史轨迹数据进行并行的梯度计算和参数更新,承担主要的 Prefix Encoding 计算负载。
D 阶段 (Decode / Simulation & Inference 模式):
计算特征:低延迟敏感、串行/增量生成、逻辑判断多。类似于 LLM 的 Decode 阶段。
硬件分配:大规模 CPU 集群(或轻量级推理卡)。
硬件选择分析:
Stage 3 的 CPU 瓶颈如何解决?:对于 Transformer 类模型,我们不再让 Actor 运行全量推理。通过 Context Offloading,长序列的编码计算被卸载至 P 阶段,Actor 仅需维护最小限度的 KV-Cache 并进行单步增量计算 (Incremental Decoding)。这使得 CPU (配合 AVX-512) 亦能高效处理大模型的单步推理。
数据局部性 (Data Locality):仿真环境 (Env) 逻辑运行在 CPU 内存中。若使用 GPU 推理,频繁的 Host-Device 数据拷贝(PCIe 传输)将成为主要开销。对于中小规模模型,传输延迟往往高于 GPU 计算带来的加速收益。
算力匹配:在运筹补货等复杂业务场景下,仿真逻辑的计算耗时往往远大于轻量级 Agent 的推理耗时。系统瓶颈在于仿真,利用低成本 CPU 核心的横向扩展能力比使用昂贵的 GPU 更具性价比。
2. 核心突破:从 O(L) 到 O(1) 的魔法
很多人会疑惑:Transformer 推理不是很重吗?CPU 怎么跑得动? 这里涉及到一个关键的计算模式转变:
通俗类比:写小说
传统模式 (Stage 3):每写一个新字,都要把前面 1000 个字重新读一遍(或者搬运沉重的记忆/KV-Cache)。随着小说越写越长,CPU 读得越来越慢,最终崩溃。这是 O(L) 甚至 O(L²) 的复杂度。
PD 架构 (Stage 4):
1
2
3
4
5
**Learner (作家/GPU)**:负责通读全文,深刻理解剧情,将复杂的历史信息压缩成一个**极简的状态向量 (Summary State)**。
**Actor (打工仔/CPU)**:不再回顾全文。它只拿着这个“极简状态”和“当前新字”,做一次极轻量的计算。
**结果**:无论历史有多长,Actor 的计算量永远是恒定的 **O(1)**。这就是 **Context Offloading (上下文卸载)** 的威力。
3. PD 架构在 RL 中的映射
Prefix (Context Encoding):历史状态的编码在 Learner 端高吞吐完成。
Decode (Action Generation):实时的动作决策在 Actor 端低延迟完成。
4. 性能红利
流水线并行:Actor 也就是“Decode”过程产生的样本,无缝流入 Learner 的“Prefill/Train”过程。
消除显存瓶颈:通过 KV-Cache 管理和计算分离,显存不再是限制 Context Length 的主要因素。
从最初的 gRPC 握手,到现在的 PD 异构协同,我们的系统演进史本质上是一部对数据流(Data Flow)控制权的争夺史。
gRPC 时代,数据流受制于网络协议。
TorchRL 时代,数据流回归内存 Tensor。
分布式时代,数据流跨越节点边界。
PD 架构时代,数据流根据算力特征智能分流。
未来,随着端到端 RL 和世界模型(World Models)的兴起,这套架构将继续进化,为 AGI 的探索提供坚实的基座。